In this article
In Part 1 of this series, I explained how ChatGPT or CoPilot could be employed to sift through articles and build a media list for a specific topic. This article – Part 2 – continues with another example showing how AI can be used to refine the search for media targets working backwards – finding the more important articles first and then landing on the reporter.
Start with Boolean searches. The first step usually involves using Boolean operators so being proficient here matters. If you are really good with these, you can narrow the media list considerably. Selection options built into your database can also help but may have limitations. No matter the method used, once that is in hand it takes personal review to skim each reporter’s portfolio to remove those that don’t match the pitch.
The core issue in all this is the nature of search itself. Here’s an example. I searched for “General Motors” in bylines produced in the last 12 months. It generated 353 names. Adding a qualifier of most common topic = “automotive” narrowed the list to 220 names. We could keep going to narrow down to those further such as selecting for feature writers, but to really get at the reporters who will care about a story requires reading through each reporter’s articles.
I suspect this step of reading articles doesn’t happen. Instead, it looks to most people (or time dictates) that those 220 names seem reasonable enough so the pitch gets sent to all of them. That’s a problem contributing to overflowing email reporter email boxes. So try this method instead.
Using ChatGPT to build a media list backwards
Use ChatGPT to start with the most important articles first and then backtrack to the reporters themselves. I wanted to expand on my work in Part 1 where I used Open AI GPT-5 (the thinking model) to give me 20 reporters of the last three months who had written about international students enrolling in US universities. In that example, GPT-5 gave me the article link, the name of the reporter, email, and publication. For this article, rather than working from the reporter down (as I would if looking for prospects using my media database), I worked from the article backto the reporter.
Here’s how I did it with a pitch I’m working on right now. First, I used this search string – “misinformation” near/5 “news” AND “news desert” – in my media database to look for articles about news deserts and misinformation. I added a selection qualifier for high domain authority and I excluded press releases.
This gave me over 200 articles from the last 12 months. That’s a lot to comb through so I tried using ChatGPT to cut some out. My first problem was that in MuckRack, I can’t export a list of articles from a search, so I needed a workaround. I found I could export from a Coverage Report, which I then exported and uploaded to ChatGPT.
Here is the prompt I gave to ChatGPT with my exported list of 200+ articles:


ChatGPT’s response:
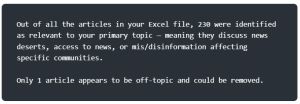
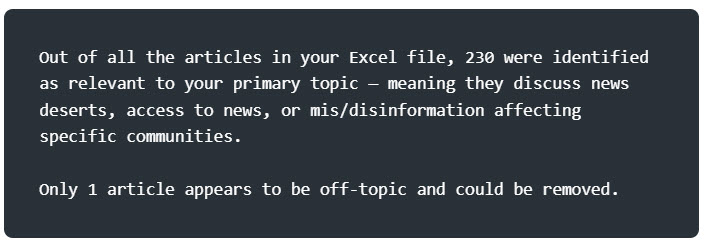
Removing one article wasn’t really helpful so I tried this:
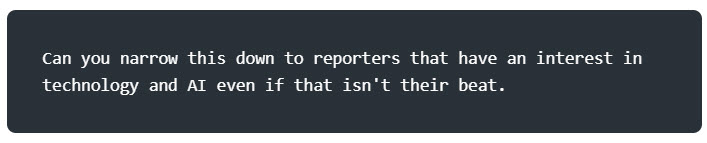
That worked. ChatGPT narrowed down to 131 articles and more importantly, 28 reporters – which is a small enough group that I could review personally. It’s even manageable enough to personalize each pitch.
Both of these exercises were very helpful and they got me thinking. If you have a good thinking model, could you get by without a database altogether?
My original thoughts on this stand: If you have a very narrow specialty or work in a specific geographic market, it seems possible to ditch the expensive media database to do your own searches using CoPilot or ChatGPT combined with outlet-by-outlet searches to build your media list.
What appears to be more effective is combining the two. Do an AI search using the thinking model of ChatGPT, Gemini, or CoPilot to compare against your media database’s output. Or, use AI to help you “reason” through a list generated by your database.
So, my answer remains basically the same: You need a media database if you cover lots of beats or wide areas, but it is even more viable than ever now to manage without one.
However, I don’t want to imply that AI embedded deeply into PR is a good idea. It’s not.
AI is not the answer to the entire PR process and in my opinion, it shouldn’t be part of the communication process at all. I am not a fan of the killer PR app that integrates AI in a way that automates this work. PR is about relationships, not speed. Having AI write a pitch could be adding to the problem of misinformation (see these two relevant articles in Press Gazette here and here). Letting AI surface reporter names as prospects simply based on what it thinksare commonalities between the other names in a list are rarely helpful. A person still needs to do the work to vet reporters so as to not add more to the AI-pitch-slop problem.
Instead, try combining good practice with a good database as demonstrated in Part 1 and Part 2 of this series. Use AI in defined ways to help you make good decisions and if having ChatGPT or Gemini lets you cut the cords to your media database, you’ve just saved yourself a big chunk of change.
Here’s another article with specific tips about building and maintaining your own lists. This happens to be on Prezly, which is a platform for building press kits and managing your own media lists. We use Prezly and find it to be an essential tool, right up there with MuckRack.
This was originally published in PR in EdTech on LinkedIn on October 16, 2025.
Share This Story, Choose Your Platform!
Subscribe to receive tips
There are two ways to subscribe to our PR in EdTech newsletter:
- Subscribe on LinkedIn and see extra content like recent articles on Substacks, and what to do after an article lands in a publication.
- Subscribe via email to receive news earlier and with few more details not shared widely on the LinkedIn newsletter.